M3 把”前沿编码 + 百万上下文 + 原生多模态”这三件通常分散在不同模型身上的事,第一次同时塞进了同一个开放权重里。它真正值得讨论的不是参数,而是几个长到能跑通一整夜的 Agent 任务——自主复现 ICLR 论文、自主优化 CUDA kernel、自主完成一个 base 模型的后训练。把这些摆在一起看,M3 的位置就很清楚了:它是从”API 升级”过渡到”Agent 主力军”的临界点。
一、为什么这次要先看「它跑过什么」,再看「它有什么」
过去两年我们评测新模型的方式,基本上是看跑分:MMLU、HumanEval、MATH。一组数字摆出来,强弱立判。
M3 的发布材料里当然也有数字——BrowseComp 智能体评测 83.5 分,比 Opus 4.7 的 79.3 高出一截。但跑分从来不是我们写这篇评测的入口。
入口是那三个长线程实验。
一个是 12 小时自主复现 ICLR 2025 杰出论文《Learning Dynamics of LLM Finetuning》:18 次 commit、23 张图表、从读论文到跑通实验全程无人干预。一个是 24 小时把一个 FP8 矩阵乘 kernel 在 NVIDIA Hopper 上做极致优化:147 次 benchmark、1959 次工具调用,硬件利用率从 7.6% 拉到 71.3%,最终实现 9.4× 加速。一个是 PostTrainBench:4 个 base 模型、12 小时内自主完成「数据合成 → 训练 → 评测 → 迭代」全流程,最终得分 37.1,位列第三(Opus 4.7 = 42.4,GPT-5.5 = 39.3)。
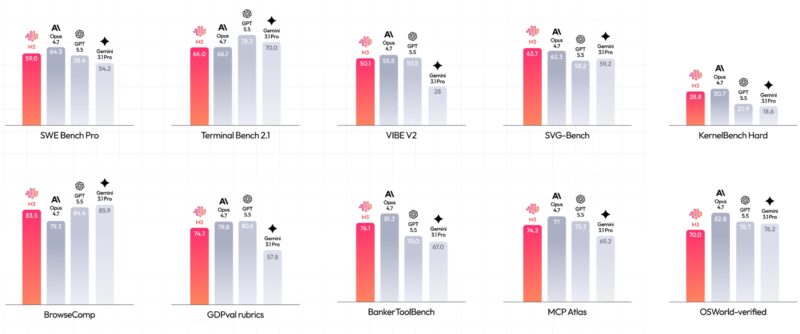
这三个任务有一个共同点:它们都不是”答一道题”,而是”自己跑完一件事“。模型要在没有人类实时监督的情况下,连续做几千次决策、读上百个文件、踩到错就回滚、跑得慢就改方案。这是 Agentic 能力,不是 chat 能力。
我们花了两周时间研究 M3 的架构和案例。结论是:M3 不是一个更强的聊天模型,它是一个能当 Agent 主力军用的工作模型。下面我们展开说。
二、架构:MiniMax Sparse Attention 让百万上下文不再贵
M3 的底座是 MiniMax 自研的 MiniMax Sparse Attention(MSA)。这个名字看起来像营销话术,但落到工程上,它解决的是一个非常具体的问题:百万上下文的推理成本。
传统 Transformer 的注意力是 O(n²) 的。上下文从 32K 扩到 1M,理论上计算量会涨 1000 倍。实操中所有号称”支持 128K / 200K 上下文”的模型,背后都做了大量妥协——要么是滑动窗口,要么是固定压缩历史 token,要么是分层 attention。M3 的做法是稀疏化:根据内容相关性动态选择要被 attention 的 token 块,而不是对所有 token 做全量 attention。
这套设计带来的直接结果有两个:
- API 最高支持 1M tokens 上下文,且至少 512K 在真实任务里可用——不是那种”理论上支持、实测 100K 就开始遗忘”的水分。
- 百万级上下文下的单次推理成本是可控的。这点对 Agent 场景至关重要:一个要跑 12 小时的 Agent 任务,会在上下文里堆积数千次工具调用的历史。context window 不只是技术指标,是 Agent 能不能”记得自己刚才在干嘛”。
MSA 不是 M3 独有的创新点,但它与 M3 的工程目标高度一致:让长线程、长上下文、长历史的 Agent 任务在合理成本下跑得起来。这与它下面要讲的多模态能力是配套的。
三、三大能力并列:编码、上下文、多模态第一次合流
M3 在产品页上把三件事并列摆出来:
1. 前沿 Coding & Agentic——不是”会写代码”,是能在长线程任务里持续决策。 2. 百万上下文(1M tokens)——支持真正的长任务历史、长代码库、长文档分析。 3. 原生多模态——不是后期拼上去的视觉编码器,是从预训练开始就吃图文混排。
这三件事单独看都不稀奇。稀奇的是三件同时出现在一个开放权重里。
我们梳理了 2026 年 6 月之前的所有主流旗舰模型。能同时做到”开放权重 + 强 Agent + 百万级上下文 + 原生多模态”的,是零。
闭源旗舰当然有同时做到的(比如 Claude、GPT 的最新版本),但它们不开放权重,且价格、速率、配额都被 API 平台严格控制。对企业用户来说,这意味着核心工作流被绑在一个黑盒上。
M3 的立场我们读得很清楚:它想把”前沿编码 + 百万上下文 + 原生多模态”三件事同时带进开放世界。从工程角度看,这是它最大的差异化,也是它对开发者和企业最有吸引力的地方。
四、长线程的真相:三个案例告诉你的事
跑分只能告诉你”模型在某道题上答得对不对”。Agent 能力要回答的是另一个问题:这个模型能不能在没有人类干预的情况下,独立完成一件需要几百步决策的事?
M3 公开的三个长线程实验,是我们认为目前最有信息密度的 Agent 评估样本。
4.1 复现 ICLR 2025 论文
任务目标是复现 ICLR 2025 杰出论文《Learning Dynamics of LLM Finetuning》。M3 拿到这个任务后,全程自主完成,耗时 12 小时,过程中产出了 18 次 commit 和 23 张图表——这些都是它自己判断时机、自己组织的产物,没有人类”这里改一下、那里再跑一次”的引导。
这件事难在哪?难在它需要模型同时理解论文、做实验设计、写代码、跑实验、出图、读图、再调整。任何一个环节卡住,整个流程就断了。M3 没有断。
4.2 CUDA kernel 优化
第二个案例更硬核。任务:在 NVIDIA Hopper 架构上优化一个 FP8 矩阵乘 kernel,要求硬件利用率尽可能高。
M3 用了 24 小时,跑了 147 次 benchmark、调了 1959 次工具调用。最终把硬件利用率从 7.6% 拉到 71.3%,实现 9.4× 加速。
这个数字的含金量要分两层看:
- 绝对值:9.4× 加速在 CUDA 优化领域是顶刊级结果。人类工程师单兵作战,能稳定做到这个数的不多。
- 方法论:M3 不是一次性给出”最优解”,它是用一千多次工具调用 + 几百次 benchmark 试出来的。这是 Agentic 范式——模型自己有一个”我想把它跑得更快”的目标,然后自己想办法。
4.3 PostTrainBench:让模型自己训自己
第三个案例是 PostTrainBench:4 个 base 模型,让 M3 在 12 小时内自主完成”数据合成 → 训练 → 评测 → 迭代”全流程。
最终得分 37.1,位列第三。前两名是 Opus 4.7(42.4)和 GPT-5.5(39.3)。
M3 在这个 benchmark 上的意义不在于”拿了第三名”——它能跑进前三本身就说明它的 agentic 能力已经进入了第一梯队。意义在于:M3 在没有任何人类干预的情况下,自己完成了一次端到端的后训练。这件事在 12 个月前还是科幻。
把这三个案例叠起来看,M3 的能力画像就清楚了:它不是某道题答得最好看的模型,它是最能在长线程任务里持续工作的模型。
五、怎么把 M3 用起来:四条接入路径
能力再强,接入成本太高也白搭。M3 在接入方式上给了四条路,覆盖从”我只是想试试”到”我要把它当生产系统核心”的不同需求。
1. API 全面支持自动 Cache 这是默认路径。自动 Cache 意味着 M3 会自己判断哪些历史对话可以复用前缀缓存,开发者不用手工管理 cache key。对长 Agent 任务来说,这一项能省掉相当一部分 token 成本。
2. Token Plan:价格不变,性能提升 简单说就是”不涨价,给你更好的模型”。这条对预算敏感但已经在用 API 的团队最友好——切换成本极低,效果立即可见。
3. MiniMax Code 平台:通用 Agent 如果不想自己拼 Agent 框架,可以直接用 MiniMax Code。这是一个把 M3 封装成”通用 Agent”的平台,开箱即用。适合个人开发者和小型团队快速验证想法。
4. 即将开源:HuggingFace + GitHub 对研究者和需要私有化部署的企业来说,这条最重要。M3 的权重将上线 HuggingFace 和 GitHub,配合 MSA 架构和长上下文支持,可以本地部署成自己专属的 Agent 引擎。具体的开源协议和商用条款,M3 团队还在最后敲定。
四条路径从轻到重,构成了一个相对完整的接入矩阵。企业用户最该关注的,是第三条和第四条:平台化 Agent 和开源私有化分别解决了”不想自己拼”和”必须自己控”两种典型需求。
六、我们对 M3 的判断
写完这篇评测,我们想跳出”参数对比”的框架,说三点主观判断。
第一,M3 的发布节奏说明 Agent 范式已经过了”演示阶段”。过去一年我们看多了”模型在 30 秒内独立完成某项任务”的 demo 视频,那些视频很酷,但生产环境需要的是”能跑 12 小时不出错”。M3 的三个长线程案例——论文复现、CUDA 优化、自训循环——是 12 小时的活。这件事的信号意义比跑分强得多。
第二,”开放 + 三能力合流”是 M3 真正的护城河。闭源旗舰当然可以单点做得比 M3 更强,但开发者真正关心的不是某一个 benchmark 上的 5 分差距,是核心工作流能不能被自己掌控。当一个企业把 Agent 系统建在闭源 API 上,定价权、速率、配额、内容策略全部不在自己手里。M3 的开放策略直接对治这个问题。
第三,落地节奏建议。如果你正在评估要不要把 M3 接入生产,先用 Token Plan 试一周。这是零成本试错路径,能让你快速判断 M3 在你的具体任务上的实际表现。如果效果好,再考虑走 API + 自动 Cache 的生产路径;如果涉及数据合规或核心业务逻辑私有化,等开源版本上线后做本地化部署评估。不要在没跑过真实任务的情况下,凭跑分表做决策。
再补一句不那么技术的观察。AI 行业过去两年最大的变化,不是某个模型又强了多少分,而是”模型能自己完成一件完整的事”这件事从不可能变成了日常。M3 是这条趋势线上的一个清晰节点。它不是终点,但它是一个让 Agent 从 demo 走向生产的临界点。
写在最后
我们对 M3 的兴趣,本质上是对”AI 能不能真正成为研发链路上的一员”这个问题的兴趣。M3 没有给出终极答案,但它给出了目前为止最让人安心的工程证据。
下一篇我们会拆 M3 的 MSA 架构细节,把稀疏 attention 在长上下文场景下的实际表现讲透。如果你在使用 M3 时遇到了具体的工程问题,欢迎在评论区交流——我们会把高频问题整理成下一篇评测的素材。
*本文由 AI 协助撰写,最终内容由本站编辑团队审核。*
*站点:blog witness · see•think•record · blog.dgqrs.cn*